Randomized Controlled Trials et al
Randomization enforces Rubin’s “Strong Ignorability”. That is, treatement assignment is independent of your predicted outcomes. This is the reason why they’re considered the Gold Standard in Biomedicine.
- They are prospective (ensures Temporality; not reconstructing what happened).
- They are interventional — you are not adjusting things post hoc.
- They are controlled — there is a comparison group (even a placebo, a non-active intervention!) The control group represents the counterfactual (kinda).
- They are randomized to balance for observed and unobserved confounders. This is the basis for any Causal Inference.
- They can be double-blinded. Knowledge of treatment can influence assignment and outcomes. If patients knew about the drug they’re taking they might report things differently. Triple-blinding is where the data analysts themselves are unaware of the assignment!
RCTs are analyzed via Intention to Treat (ITT). This means that if you have patients who are non-adherent or drop out, you do not remove them from your study. There might have been a reason why they left. If you remove them it’s a bit like adding another arm to your study.
You also want to minimize loss to follow-up to ensure the validity of effect estimates and prevent attrition bias.
The entire point of all this is ‘simply’ to make sure that the treatement and control arms are as similar as possible!
Internal Validity
RCTs are Explanatory Trials which minimize noise and emerge effect size. Note that these trials are under ideal conditions! Typically, the more you optimize for internal validity the more your external validity (generalizability) suffers.
So how can you get the benefits of RCTs and good external validity?
Pragmatic Clinical Trials (PCTs)
Explanatory Trials → Efficacy (ideal conditions)
Pragmatic Trials → Efficiency (real world)
| RCT | PCT | |
|---|---|---|
| Eligibility | Narrow | Broader |
| Setting | Academia/Resesarch | Everyday Clinical practice |
| Intervention | Strict | Flexible; real-world-ish |
| Outcomes | Efficacy Endpoints | Connected to patient, relevant to their care |
| Adherence | Maniacally monitored (complete follow up) | Allow people to be people |
Note that we’re still randomizing. Note that the FDA doesn’t like PCTs lol.
Why Use Them?
They’re more grounded in the Real World™ (use data from systems where care is already happening), are less disruptive to the patient and researcher, and are more efficient in comparison.
How do you use them?
Trial is designed before data collection begins. Patients are identified in real time using EHR records or clinical workflows. Randomization can be at the individual (or cluster) level and any exposures/interventions are done as part of the clinical care.
Perhaps the biggest problem here is that you are not in control and you’re ceding control to people outside your control. This requires a lot of buy-in!
Now you can do PCTs prospectively and retrospectively.
Design Options
| Notes | Prospective PCT | Retrospective PCT | |
|---|---|---|---|
| Cluster Randomized Trials | Yes | None | |
| TODO: Finish this… |
Quasi-Experimental Methods
You estimate causal effects in settings where the hallowed randomization is not feasible and you still want the coolness of RCTs. What if you cannot find a control group? Think microplastics… whom can you find who doesn’t have them?
Interrupted Time Series (ITS)
Time Series data is simple (just remember evenly spaced intervals). The “interrupted” part refers to some point in the time axis where something happened (an intervention may have been introduced). Think Outcome vs. Time.
If you see a level change or a slope change or both, ‘something’ affected the outcome at that point in time. Note that you can do this retrospectively as well.
Segmented Linear Regression
You slice up a single regression line into two or more pieces/segments and estimates slope and intercept for each one.
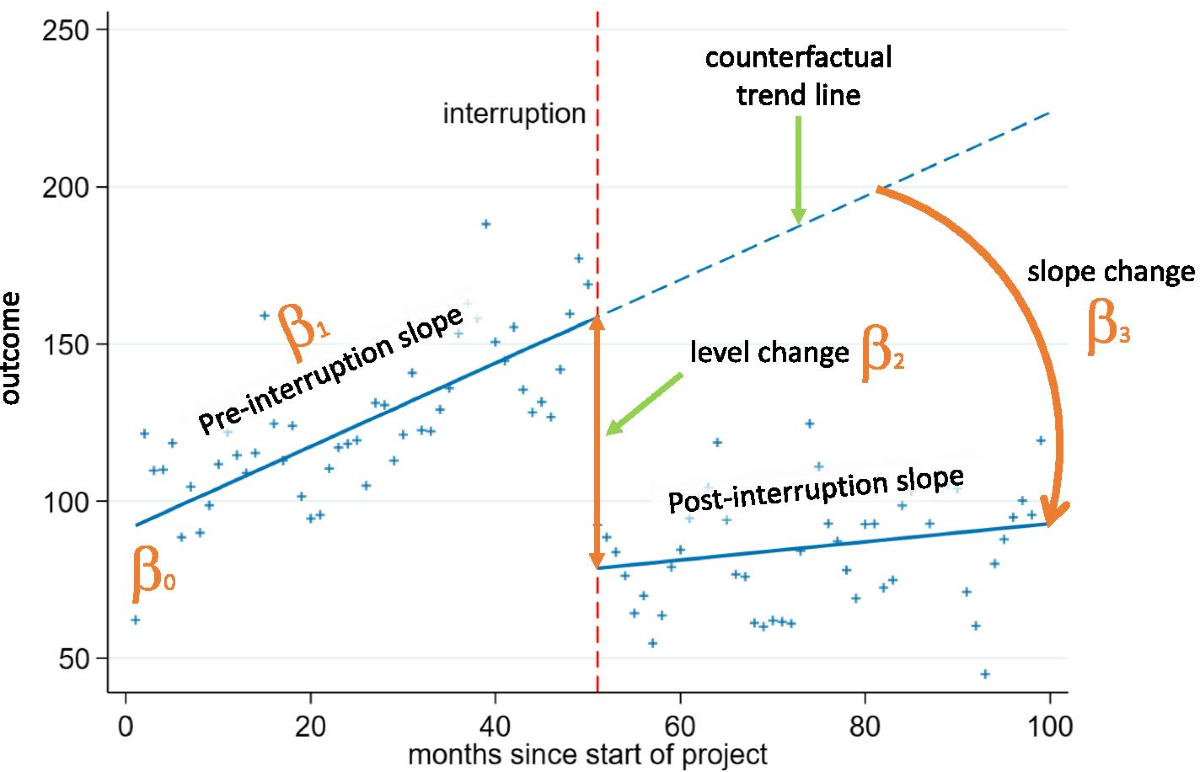
Problems/Assumptions:
- Need 8-12 time points at a minimum (Rule of Thumb)
- Assume linearity
- One and clear interruption point
There’s also problems with autocorrelation (observation is related to its previous value; iid is assumed in regression; if you ignore you can increase Type I errors (TODO: how?)) and seasonality (flu season; can confuse with intervention effects!)
Several ways to deal with former: ARIMA, add lagged outcome variable (use as a predictor). You can also use Newey-West standard errors (TODO: wtf is this?)
As for seasonality, you can add a binary indicator for calendar time period. You can actually add Fourier terms for “waves” to represent seasonality! You can use SARIMA which is Seasonal ARIMA!
How do you even choose a design?
- Intervention — Is it randomizable? Is there some notion of clear timing?
- Do you have a control group?
- Data, Data, Data — Do you have repeated observations? Can you even model any trends? What are the inductive biases of your model?
- Is the randomization even doable?
- Is the randomization ethical?