Analysis of Cohort Studies
Cohort studies are observational studies. We analyze cohort studies using tabular methods and ML methods.
Tabular methods
You can use a 2x2 table to calculate a bunch of stuff.
| O+ | O- | |
|---|---|---|
| E+ | a | b |
| E- | c | d |
Risk Ratio is the probability of the outcome in the exposed divided by the probability of outcome in unexposed group:
You really use CIs If the CI includes one, it is not significant. Now for continuous distributions, you use a t-test. Note that you can’t use the z-test because with that you are assuming that you know the population variance!
Linear Regression
Note that will give you an average.
Error terms: assume normality, assume constant variance (homoscedasticity, hetero otherwise).
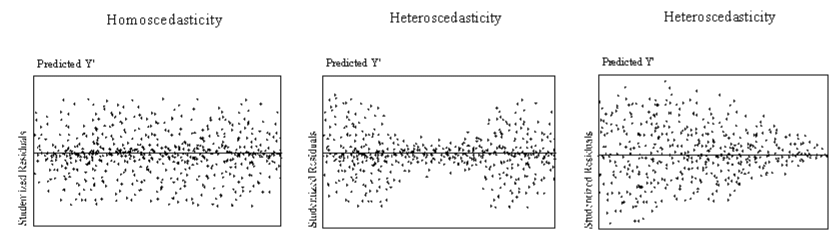
Use in Hypothesis Testing for Cohort Studies
You make a table, get the regression equation, you are now trying to make epidemiological assertions.
You can calculate the t-statistic. Another way is
Non-parametric bootstrap methods: Sample randomly (with replacement), run regression for each get for runs. Sort by values, get 2.5th and 97.5th percentiles, compare with… TODO?
If you approach with a causal lens, you can answer a lot of epi questions. DAGs are good for this (Rothman calls them SWIGs, Single World Intervention Graphs). You express a relationship and estimate its effect size with regression (just one way, there are others) and DAGs. You can draw these things:
A Main Effect is simply X -> Y.
Covariates affect outcomes but are not associated with other features. X -> Y and confounder C -> Y.
Confounders are outside the causal pathway that distort the causal relationship between effect and outcome. Now you can test if something is a confounder by having
Now if changes across these two by more than , you conclude that is a confounder.
Statistical Interaction is another. X -> C -> Y in addition to X -> Y.
Now you look at . If it is more than zero you conclude that there is some interaction.
Another is Mediation: X -> M -> Y
Now: if any in any one of models 1-3 is low, you conclude there is very little mediation.
Cohort studies, DAGs, and regression work as a unified framework for Computational Epidemiology.
TODO
- Why must the outcome be continuous if the exposure is binary for a regression?