Bias and Variance
This is written from a Machine Learning perspective. TODO: Write this to calm statisticans.
Bias
This is named appropriately. Your model knows only giraffe and donkey. You put it out into the world. You show it a tree, a bicycle, and an opera house. It’s dumb. How do you think it’ll do?
Put another way: Your model only knows straight lines or completely ‘flat’ hyperplanes in higher dimensions as “decision boundaries”. You put it out into the world. You ask it to classify stuff that looks like this. It’s dumb. How do you think it’ll do?
- High Bias will lead to underfitting.
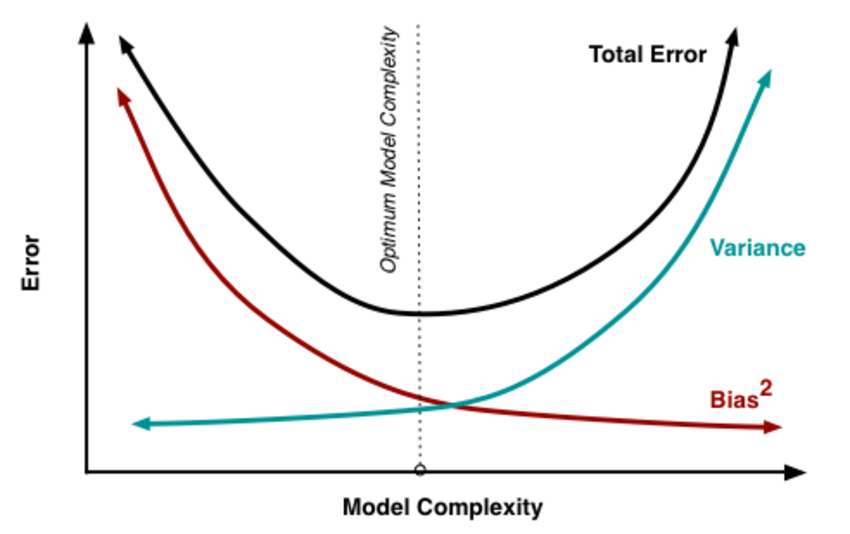
- You can reduce bias by making your model smarter and/or increasing the things it ‘sees’. Increase the complexity (e.g. # of parameters). This is why the bias goes down with model complexity in the graph at the bottom.
Variance
Bit of a doozy. Stats and ML majors memorize: “High Variance ⇒ Overfitting”. How?
Variance here means “How well does my model do on another dataset?” I.e., a dataset that’s not the one used to train it. “High Variance” means your model shits itself on new data it’s never seen before: if and your model’s not doing so well on new data, will go up.
Variance really underscores the importance of the Train/Validation/Test split and doing this properly. You can see really nice results (low Variance) in Train but high variance in Test. That’s a sign that your model is memorizing things and not capturing some generative signal (which is the hallowed goal of all modeling, and however vaguely.)
Doggo Explanation
Ye Olde Tradeoff
You want a model that has low bias and low variance. But the Real World™ is not like that. What if we had to pick? Rule fof Thumb: We generally prefer low variance over high bias. High Variance means overfitting and we want to train our little model to succeed in delivering Shareholder Value™ in fast-paced dynamic environments.
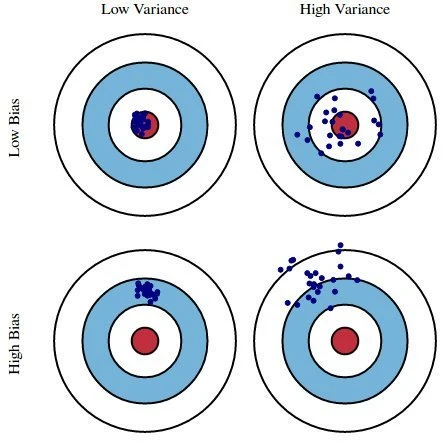
Dartboard Analogy
Borrowed from Physics textbooks re: Precision and Accuracy. Used a lot, I’m meh about it. Read the above.